
Colaboración especial de Marc Durán ( Becario Sicómoro en el Máster de Física de los Sistemas Complejos del IFISC)
Introducción
Los incendios son potencialmente uno de los desastres naturales más destructivos y peligrosos para los bosques debido a que pueden provocar pérdida de la biodiversidad que poseen, el empobrecimiento en la calidad de su suelo y la reducción de su capacidad para capturar el CO2; como muestra una variedad de estudios realizados al respecto desde diferentes disciplinas.
Por ello la necesidad de delimitar las áreas boscosas en términos de su susceptibilidad a los incendios se ha convertido en una prioridad para quienes trabajan en temas vinculados con la protección civil o la gestión de catástrofes; pues identificar áreas con alto riesgo de incendio es importante para diseñar con éxito planes de prevención y asignar recursos para su extinción.
Una vez dicho esto, ¿cómo podemos prevenir un incendio de manera eficiente y viable hoy en día? La respuesta la encontramos en dos términos de los que se habla mucho últimamente: Big Data y Machine Learning.
La revolución del Big Data
El Big Data es un término que describe el gran volumen de datos que nos inundan. Gracias al avance de la tecnología hoy en día tenemos muchos datos de todo tipo al alcance, por lo que el análisis de datos y el “machine learning” desempeñan un papel muy importante en el mundo científico.
 Figura 1: Big data
Figura 1: Big data
El análisis de datos es un proceso que se basa en la exploración, transformación y examen de los mismos para identificar tendencias y patrones que revelen información importante sobre ellos y que no resulta evidente deducir a partir de medios tradicionales.
Por su parte el “machine learning”, conocido como aprendizaje automático, es una rama de la inteligencia artificial dentro de las ciencias de la computación, que busca imitar la inteligencia y el comportamiento humano. En concreto, con el “machine learning” hacemos que las máquinas aprendan sin ser expresamente programadas para ello, por ejemplo, hacer predicciones de diverso tipo a partir de una información obtenida gracias al análisis de una serie de datos.
Esta tecnología está presente en un sinfín de aplicaciones que usamos a diario como las recomendaciones de Netflix o Spotify, el habla de Siri y Alexa, etc., demostrando su eficacia y utilidad en diversos ámbitos.
Volviendo a la pregunta de este post, cómo podríamos usar estas técnicas para predecir si ocurrirá un incendio en una zona concreta. Esto se logra mediante un interesante proceso que expondremos a continuación
Metodología de investigación
En primer lugar, como paso fundamental, necesitamos recopilar la mayor cantidad de datos posibles de la zona que estemos estudiando. Lo cual nos dará información acerca de factores como la humedad, el viento, la temperatura, si previamente ha habido incendios en la zona o no; así como el día, el mes y el año que ocurrieron.
Tomaremos como ejemplo una serie de datos correspondientes a zonas de clima mediterráneo del norte de Argelia (ref.1). Una vez se dispone de estos datos nos preguntaremos ¿qué análisis podemos hacer a partir de ellos?, y ¿cómo llevarlo a cabo?
Usando diferentes técnicas de estadística descriptiva podemos convertir gran cantidad de esos datos en información valiosa para nuestro propósito, la cual nos dará indicaciones relevantes como en qué mes del año llueve más, en qué meses se producen las sequías y con qué factores suelen venir acompañados estos fenómenos.
Para entender mejor esta información y utilizarla en la búsqueda de respuestas a nuestras preguntas, la mejor opción suele ser organizarla en tablas o gráficos que permiten visualizarla. Como los que se presentan a continuación:
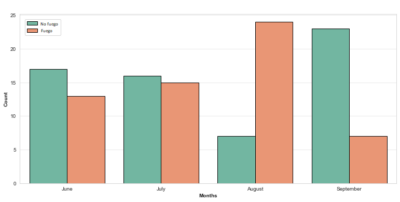
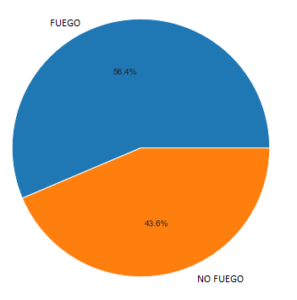
Figura 3: En la izquierda número de incendios por cada mes y en la derecha el total de fuegos y no fuegos en porcentaje.
Una vez visualizados los datos, ¿Cómo podemos predecir si va a haber o no un incendio en el día X con ciertas condiciones climáticas?
Es aquí donde interviene el Machine Learning.
El siguiente paso en el trabajo es diseñar un algoritmo (un conjunto ordenado de pasos que permiten llegar a un resultado) que sea capaz de identificar patrones a partir de los datos que le estamos suministrando para obtener como conclusión la respuesta a nuestra pregunta.
Es decir, identificará y detectará que condiciones climáticas se dieron los días que hubo un incendio: si fueron días secos, hubo altas temperaturas, la velocidad de los vientos, el sentido en el que soplaban, etc. De esta manera si la próxima semana se dan en la misma zona geográfica idénticas condiciones es previsible que también se produzca un incendio, o exista un alto riesgo de que se produzca.
Pese a que esto constituye una información valiosa estas investigaciones no se detienen aquí y aún podemos ir más allá. También podemos utilizar un segundo algoritmo para predecir, en el caso de que haya un incendio, qué gravedad va a tener éste. Aumentando con ello la calidad de la información que proporcionamos y su utilidad.
Un aspecto para tener en cuenta es que estos algoritmos no hacen uso de la totalidad de los datos que se les proporciona, debido a que se encuentran en una fase de “aprendizaje” autónomo selecciona una parte de esos datos, normalmente el 70 %, para entrenarse y realizar las predicciones mientras los datos restantes, el 30 %, son usados para comprobar si ha predicho correctamente y por tanto confirmar si el proceso de aprendizaje resulta exitoso
Proceso que implica una cierta complejidad técnica cuya explicación trasciende los objetivos de este escrito. Pero sigamos con nuestro ejemplo.
Resultados
Una vez aplicado los algoritmos de “machine learning” podemos ver si los resultados son buenos comparándolos con los obtenidos a partir del 30% de los datos que habíamos separado.
Para la pregunta sobre si va a haber fuego o no en la zona que estamos estudiando, elaboramos una tabla comparativa en la que si hay fuego ponemos un 1 y si no hay fuego un 0. Vemos en la columna de la izquierda lo que realmente paso, y en la columna de la derecha lo que ha predicho nuestro modelo.
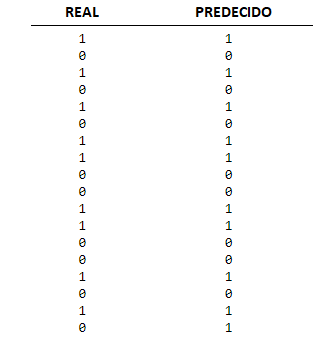
Figura 3: Resultado de nuestro algoritmo prediciendo si habrá fuego o no.
Podemos ver que se asemeja mucho. El algoritmo predijo el resultado correcto con un 97, 9% de acierto.
Por otro lado, en el caso de que haya un fuego, que gravedad tendría éste, vemos en la columna de la izquierda la que realmente tenía, y en la columna de la derecha la que predice nuestro modelo. Esta gravedad está expresada con un valor numérico, cuanto mayor sea este más grave será el incendio.
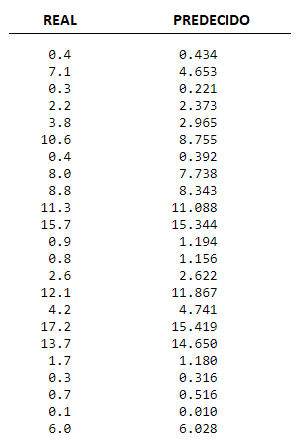 Figura 4: Resultado de nuestro algoritmo al predecir la gravedad que tendría el incendio
Figura 4: Resultado de nuestro algoritmo al predecir la gravedad que tendría el incendio
Podemos ver que se asemeja mucho también. El algoritmo a predicho el resultado correcto con un 96, 6% de acierto.
Conclusiones
Basta con dar un breve vistazo a esos resultados para comprobar el enorme potencial con que cuentan estas nuevas técnicas emergentes, capaces de ofrecernos valiosa información de gran utilidad práctica en la toma de diversas decisiones. Lo cual explica, entre otras, el gran protagonismo adquirido por la ciencia de datos y su inmensa proyección hacia el futuro.
Está fuera de toda duda que seguiremos capturando datos y es previsible que perfeccionaremos el nivel de detalle en dichas capturas, aumentando la necesidad de herramientas y métodos que permitan trabajar con ellos para llegar a obtener conclusiones útiles.
Campo de trabajo donde la física de los sistemas complejos está demostrando su gran importancia, gracias a su capacidad para recolectar y sistematizar grandes volúmenes de datos, logrando obtener a partir de ellos conclusiones y modelos que podemos aplicar en problemáticas concretas.
Considero que lo más interesante de esta metodología reside en su capacidad de aplicarse a diferentes ámbitos, ofreciendo soluciones prácticas a problemáticas como la lucha contra incendios, prevenir enfermedades, el diseño del sistema de distribución eléctrica, la seguridad de redes informáticas o de redes de transporte como las redes de metro de grandes ciudades, etc.
Aunque en un primer momento todo esto pueda parecernos un desarrollo completamente actual en realidad no lo es tanto, porque el ser humano siempre ha recolectado datos para solucionar los problemas que lo afectaban. Lo que resulta verdaderamente nuevo es la gran cantidad de datos de la que disponemos ahora y nuestra capacidad para trabaja con ellos. La cual pasa por del diseño de nuevas metodologías específicas para procesarlos.
Un científico de datos podría asemejarse a ese pastor de tiempos pasados que pese a no haber estudiado física o meteorología, al llevar toda su vida sacando su rebaño a pastar identificaba la importancia de factores como las nubes, la temperatura o la velocidad del viento para deducir si un día concreto llovería o no.
Pero en realidad las capacidades del científico de datos van mucho más allá, pues tiene una metodología que no solo le permite contar con los conocimientos y experiencia del pastor sino que, gracias a la avalancha de datos con los que contamos actualmente, puede disponer del acervo de conocimientos y experiencias de otras profesiones. Convirtiéndose en un perfil polivalente, dotado con herramientas y metodologías que le permiten resolver problemas de gran complejidad de una forma más eficaz.
Referencias
https://archive.ics.uci.edu/ml/datasets/Algerian+Forest+Fires+Dataset++




{kind=link}
{kind=link}
{kind=link}
{kind=link}
Felicidades Marc, un gran articulo. Te ánimo a seguir aportando tus conocimientos y ganas de investigar, al mundo de la ciència, vuestros esfuerzos mejoran nuestro día a día.